Hay un patrón que vemos en cada empresa que auditamos: nadie sabe cuánto cuesta nada. Los engineers despliegan servicios, los escalan, y siguen adelante. La factura llega 30 días después, y para entonces ya es demasiado tarde para entender dónde fueron a parar esos $80.000.
La solución no es una mejor herramienta de facturación — es hacer visibles los costos en tiempo real, en los mismos dashboards que los engineers ya usan. Armamos un dashboard de FinOps con Grafana, Prometheus y algunos exporters custom, y cambió la forma en que todo el equipo de ingeniería piensa en infraestructura.
El problema de fondo: los datos de costo siempre llegan tarde
AWS Cost Explorer te muestra lo que gastaste ayer. Kubernetes no tiene un concepto nativo de costo. El resultado: los engineers toman decisiones de recursos sin ningún feedback de costos.
Imaginá manejar un auto donde el velocímetro muestra la velocidad de ayer. Eso es lo que se siente gestionar costos de cloud sin visibilidad en tiempo real.
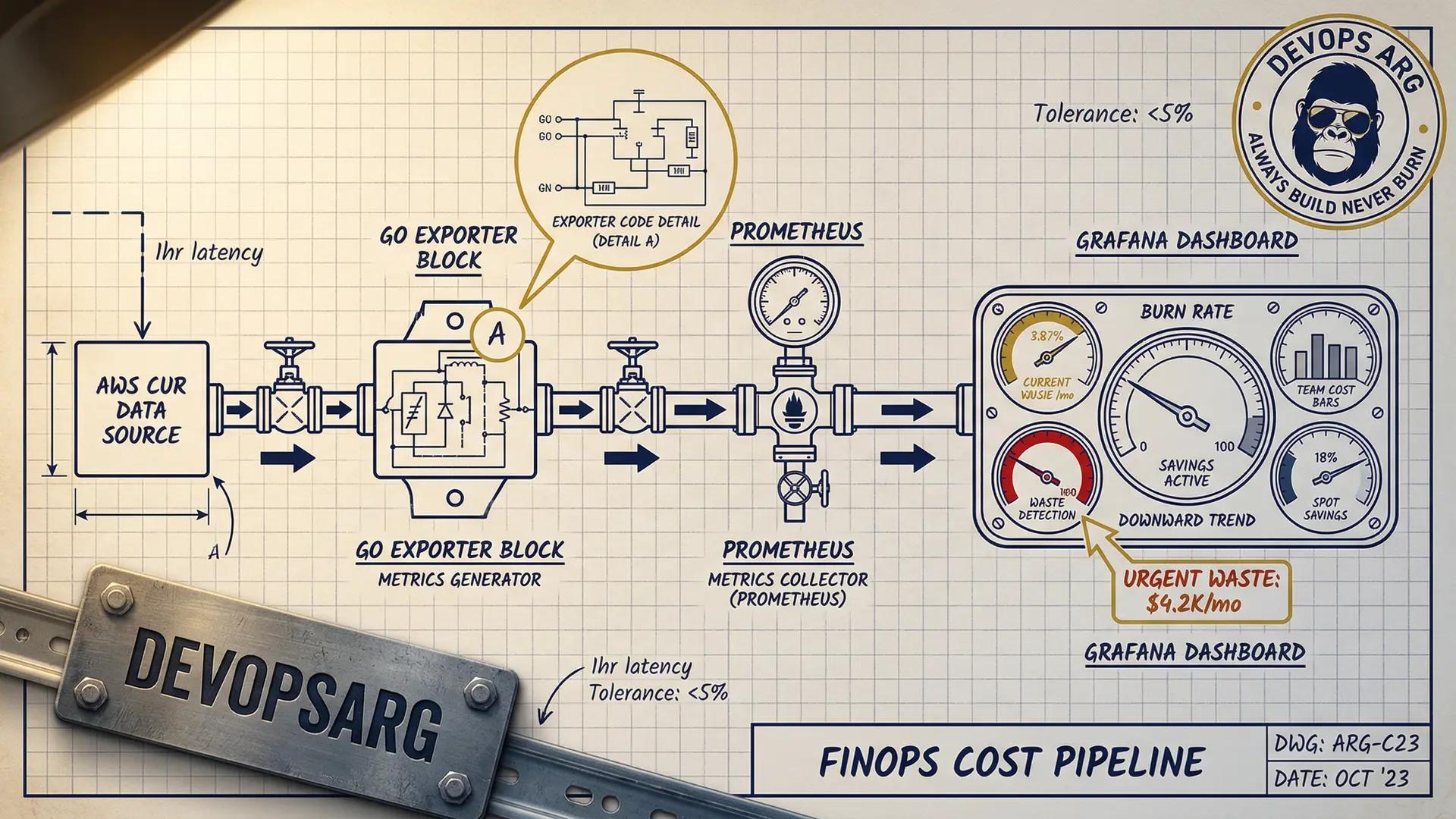
Arquitectura: el pipeline de datos de costo
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ AWS CUR │────▶│ Custom │────▶│ Prometheus │
│ (Cost & │ │ Exporter │ │ │
│ Usage) │ │ (Go binary) │ │ │
└──────────────┘ └──────────────┘ └──────────────┘
│
┌──────────────┐ ┌──────────────┐ │
│ Kubecost │────▶│ /metrics │────────────┤
│ (pod-level) │ │ endpoint │ │
└──────────────┘ └──────────────┘ │
│
┌──────────────┐ ┌──────────────┐ │
│ Spot prices │────▶│ Spot Price │────────────┘
│ (AWS API) │ │ Exporter │ │
└──────────────┘ └──────────────┘ ▼
┌──────────────┐
│ Grafana │
│ Dashboard │
└──────────────┘
Tres fuentes de datos alimentan a Prometheus:
1. AWS Cost & Usage Reports (CUR)
Escribimos un exporter pequeño en Go que lee los datos del CUR de AWS desde S3 (actualizado cada hora) y los expone como métricas de Prometheus:
// Versión simplificada — el exporter real tiene ~300 líneas
costGauge := prometheus.NewGaugeVec(
prometheus.GaugeOpts{
Name: "aws_cost_hourly_dollars",
Help: "Hourly AWS cost by service and account",
},
[]string{"service", "account", "region"},
)
// Consulta el bucket S3 de CUR cada hora
func updateCosts() {
records := parseCUR(downloadLatestCUR())
for _, r := range records {
costGauge.WithLabelValues(
r.Service, r.Account, r.Region,
).Set(r.BlendedCost)
}
}Esto nos da métricas como:
aws_cost_hourly_dollars{service="AmazonEC2"}→ $12,40/hraws_cost_hourly_dollars{service="AmazonRDS"}→ $3,20/hr
2. Kubecost para costos por pod
Kubecost asigna los costos del cluster a pods individuales en función del consumo de recursos. Expone métricas de Prometheus out of the box:
# Costo por namespace por hora
sum(
kubecost_allocation_cost_total{cluster="production"}
) by (namespace)Esta es la métrica mágica — te dice exactamente qué equipo o servicio está gastando cuánto.
3. Exporter de precios Spot
Un exporter mínimo que extrae los precios Spot actuales desde la API de EC2:
aws_spot_price_dollars{instance_type="m5.xlarge", zone="us-east-1a"}Lo usamos para calcular cuánto estamos ahorrando versus los precios On-Demand.
El dashboard: 4 paneles que cambiaron todo
Panel 1: Burn rate diario (número grande)
El panel de mayor impacto es el más simple: un número enorme que muestra el gasto proyectado del día.
# Costo diario proyectado basado en la tasa de burn actual
sum(rate(aws_cost_hourly_dollars[1h])) * 24Cuando los engineers ven "$1.847/día" en rojo brillante, le prestan atención.
Panel 2: Costo por equipo/namespace
Un gráfico de barras apiladas que muestra el desglose de costos por namespace de Kubernetes (cada namespace = un equipo):
sum(
kubecost_allocation_cost_total{cluster="production"}
) by (namespace)Esto generó una competencia sana entre los equipos. Nadie quiere ser la barra más cara del gráfico.
Panel 3: Detección de desperdicio
Una tabla que muestra los pods con requests de recursos altos pero uso real bajo:
# Ratio de desperdicio de CPU: solicitado vs usado
(
sum(kube_pod_container_resource_requests{resource="cpu"}) by (pod, namespace)
-
sum(rate(container_cpu_usage_seconds_total[5m])) by (pod, namespace)
)
/
sum(kube_pod_container_resource_requests{resource="cpu"}) by (pod, namespace)
> 0.7 # Más del 70% de desperdicioEste panel solo identificó $8.000/mes en recursos desperdiciados el primer día.
Panel 4: Ahorros Spot vs On-Demand
Un contador en tiempo real que muestra los ahorros acumulados por usar Spot:
# Ahorros mensuales por Spot
sum(
(aws_ondemand_price_dollars - aws_spot_price_dollars)
* on(instance_type) group_left
kube_node_labels{label_karpenter_sh_capacity_type="spot"}
) * 730 # horas por mesVer "$18.400 ahorrados este mes" en verde hace sentir bien a todo el mundo con la migración a Spot.
Alertas: detección de anomalías de costo
Los dashboards están muy bien, pero las alertas detectan los problemas más rápido. Configuramos tres tipos:
Detección de spikes
# Alerta si el burn rate por hora sube un 50% sobre el promedio de 7 días
- alert: CostSpike
expr: |
sum(rate(aws_cost_hourly_dollars[1h]))
>
1.5 * avg_over_time(sum(rate(aws_cost_hourly_dollars[1h]))[7d:1h])
for: 30m
labels:
severity: warning
annotations:
summary: "Spike de costo detectado: {{ $value | humanize }}/hr vs normal"Umbral de presupuesto
# Alerta al 80% del presupuesto mensual
- alert: BudgetWarning
expr: |
sum(increase(aws_cost_hourly_dollars[30d])) > 12000 # $15K presupuesto * 0.8
labels:
severity: warningDetección de recursos ociosos
# Alerta sobre pods que corren pero no reciben tráfico
- alert: IdlePods
expr: |
sum(rate(http_requests_total[1h])) by (deployment) == 0
and
sum(kube_deployment_spec_replicas) by (deployment) > 0
for: 6hEl impacto cultural
El dashboard cambió el comportamiento más de lo que cualquier política hubiera podido:
Antes: los engineers nunca veían los costos. El over-provisioning era el default porque "es más seguro". Nadie optimizaba porque no había visibilidad.
Después: cada equipo revisa su panel de costos en el standup semanal. Los engineers empezaron a hacer right-sizing de forma proactiva porque podían ver el desperdicio. Tres equipos pidieron migrar a Spot de forma independiente después de ver el panel de ahorros.
Un engineer lo resumió mejor que nadie: "Antes pensaba que los costos eran un problema de otra persona. Ahora puedo ver que mi servicio cuesta $340/día y sé exactamente qué pods son los responsables."
Tiempo de setup y mantenimiento
| Componente | Tiempo de setup | Mantenimiento ongoing |
|---|---|---|
| Exporter de CUR | 1 día | Mínimo (auto-actualizable) |
| Kubecost | 2 horas | Helm upgrade trimestral |
| Exporter de Spot | 4 horas | Ninguno |
| Dashboards de Grafana | 1 día | Agregar paneles según necesidad |
| Alertas | 4 horas | Ajustar thresholds mensualmente |
Total: aproximadamente 3 días de trabajo. El dashboard se paga solo en la primera semana.
Qué haríamos diferente
Arrancar con los alertas antes de los dashboards. Armamos primero los paneles visuales porque son más impactantes para mostrarle a la gente, pero los alertas son los que atrapan los problemas reales. Si tuviéramos que hacerlo de nuevo, configuraríamos al menos la detección de spikes el día uno.
No subestimar el trabajo de etiquetado. El valor real de la asignación de costos por namespace depende de que los recursos estén bien etiquetados. Nos llevó más de una semana limpia de auditoría de tags antes de que los datos empezaran a tener sentido. Estructurá tu taxonomía de tags antes de instalar Kubecost.
Comunicar el dashboard antes de mostrarlo. La primera vez que un equipo ve que su namespace consume el 40% del presupuesto del cluster, la reacción puede ser defensiva en vez de constructiva. Preparar el terreno — explicar que el dashboard no es para auditar a nadie sino para ayudar a todos a optimizar — marcó la diferencia entre la adopción y la resistencia.
¿Querés un dashboard de FinOps para tu equipo? Desplegamos este stack en menos de una semana. Hablemos.